Apps created with Calcapp are typically used to perform numeric calculations, but you can also process text. We support most of the text-processing formula functions spreadsheets offer. These are the most frequently-used text functions (there’s more information in the reference sidebar):
-
LEN returns the length of a text string.
LEN("Abc")returns 3. -
REPT repeats a text string a given number of
times.
REPT("Abc", 3)returns “AbcAbcAbc”. -
LEFT, RIGHT and
MID are used to extract text using indices.
LEFT("Abc", 2)returns “Ab”, the first two characters counting from the left-hand side, andRIGHT("Abc", 2)returns “bc”.MID("Abc", 2, 1)returns “b”, because “b” starts at position two and has a length of one. -
TRIM removes excess space characters from a text
string.
TRIM(" Abc ")returns “Abc”. -
LOWER and UPPER convert text to
lower-case and upper-case, respectively.
LOWER("Abc")returns “abc” andUPPER("Abc")returns “ABC”. -
FIND searches a text string nestled within another
text string and returns its position.
FIND("bc", "Abc")returns 2, because “bc” starts at that index in “Abc”. -
REPLACE replaces part of a text string, identified
using numeric indices, with a different text string.
REPLACE("Abc", 1, 2, "De")returns “Dec”. -
SUBSTITUTE substitutes new text for old text in a
text string.
SUBSTITUTE("Abc", "Ab", "De")also returns “Dec.”
While these functions are quite versatile, there are many things they cannot easily do, including:
- Determining if a text string represents a phone number.
- Ensuring that a password starts with a letter and is followed by any number of letters or numbers.
- Extracting the fourth word from a sentence.
- Replacing the fourth word in a sentence with the third word from the same sentence.
Three new text-processing functions enable this and more. What they have in common is that they expect you to write so-called regular expressions.
Calcapp’s regular expression dialect
A regular expression is a specially-crafted text string which can be used to find text strings within other text strings. They are very powerful, but can also be difficult to understand. There are entire books devoted to the topic (including the Calcapp team’s favorite book on the subject) and numerous online tutorials (here’s one we like to use). In this post, we’ll provide a basic introduction, but you’ll have to consult other sources to truly master regular expressions.
Spreadsheets don’t typically support regular expressions. Google Sheets, however, supports the three functions REGEXMATCH, REGEXEXTRACT and REGEXREPLACE. REGEXMATCH returns whether a text string matches a regular expression, REGEXEXTRACT extracts parts of a text string using a regular expression and REGEXREPLACE replaces parts of a text string, again using a regular expression.
We have modeled our three new functions after the Google Sheets functions, but our functions offer features that go beyond Google’s offering. The new functionality is offered through optional parameters to the Calcapp functions, meaning that you should be able to copy and paste formulas which use REGEXMATCH, REGEXEXTRACT and REGEXREPLACE directly from Google Sheets and have them work correctly in apps you build with Calcapp.
Regular expressions are part of lots of products and they often use dialects which aren’t quite compatible with one another. Google Sheets uses a dialect called RE2 and Calcapp uses the JavaScript dialect (with certain additions).
Introducing regular expressions through the REGEXMATCH function
The REGEXMATCH function is the most basic function Calcapp offers that uses regular expressions. It returns TRUE if a text string matches a regular expression and FALSE otherwise. The first parameter is the text string which may or may not match the regular expression, which is given as the second parameter.
Does “bc” appear within “Abc”? The following formula returns TRUE to
indicate that it does: REGEXMATCH("Abc",
"bc").
Of course, you can determine the same thing with the FIND function. The true value in regular expressions is their support for special characters, which can match not just literal characters but entire classes of characters, such as all letters, all numbers or even all vowels, and more.
Matching a number
Some special characters are preceded by a backslash character, like
\d, which
matches a single number. That means that REGEXMATCH("5", "\d")
returns TRUE but REGEXMATCH("a", "\d")
returns FALSE.
You can also spell out a number of permitted characters by enclosing
them in brackets. [0123456789] is
equivalent to \d, meaning that
REGEXMATCH("5",
"[0123456789]") also returns TRUE.
Within brackets, you can use character ranges. [0-9] means “zero
through nine” and is, again, equivalent to [0123456789] and
\d.
Matching a letter and whitespace
Character ranges work for letters too, so [a-z] matches all
lower-case letters in the English alphabet, [A-Z] matches all
upper-case letters and [a-zA-Z] matches all
letters, regardless of case. [^a-z] is a negated
character range (note the caret at the beginning) and matches
any character which is not a lower-case letter. REGEXMATCH("(",
"[^a-z]") returns TRUE, because the opening parenthesis is not
a letter.
There is also the special character \w, which is equivalent
to [a-zA-Z0-9_] and thus
matches any letter, digit or underscore. \s matches any
whitespace character, which is an invisible character such
as an actual space or a tab character.
Putting it all together, REGEXMATCH("Abc10",
"[A‐Z][a‐z][a-z]\d\d") returns TRUE, but
REGEXMATCH("Abc1",
"[A‐Z][a‐z][a-z]\d\d") returns FALSE, as
the regular expression expects two trailing numbers.
Repetition
To handle repetition, regular expressions offer “curly braces,” which
you use to specify the number of characters you expect. \d{3} is equivalent to
\d\d\d and
only matches three digits. \d{3,5} matches three
digits, four digits or five digits, meaning that REGEXMATCH("four",
"[a-z]{3,5}") returns TRUE, as “four” has four characters.
\d{3,}
matches at least three digits and \d{,3} matches at most
three digits.
Use the special character + to indicate that one
or more characters are accepted, * to indicate that zero
or more characters are accepted and ? to indicate that zero
or one character is accepted. REGEXMATCH("Abc10",
"[a-zA-Z]+[0-9]+") returns TRUE, as does REGEXMATCH("A1",
"[a-zA-Z]+[0-9]+"), as the regular expression only stipulates
that the text string must have one or more letters followed by one or
more numbers. [a-zA-Z]*[0-9]* (note
that the +
has been replaced by *) actually accepts
zero letters followed by zero numbers, meaning that REGEXMATCH("1",
"[a-zA-Z]*[0-9]*") returns TRUE, as does REGEXMATCH("",
"[a-zA-Z]*[0-9]*"). [a-z]?\d matches a
letter followed by a number but also matches just a number, as the
question mark makes the letter optional.
Use parentheses to repeat entire expressions. While \d{3} matches exactly
three digits, (\d[a-z]){3} matches a
number followed by a letter, but only if this combination is repeated
three times. REGEXMATCH("1a2b3c",
"(\d[a-z]){3}") returns TRUE, but REGEXMATCH("1a2b",
"(\d[a-z]){3}") returns FALSE (the third repetition is
missing).
Alternation
Parentheses can also be used to specify alternation in a
regular expression in conjunction with the special character,
|.
Alternation here means “either or,” in the sense “match this text
string or match that other text string.”
As a simple example, REGEXMATCH("this",
"(this|that)") and REGEXMATCH("that",
"(this|that)") both return TRUE.
Matching any character
The period is a special character in regular expressions, as it
matches anything. .+\d matches any number
of characters followed by a number, meaning that REGEXMATCH("test1",
".+\d") returns TRUE but REGEXMATCH("0", ".+\d")
returns FALSE (there must be a character — any character — before the
number).
[^\d]+\d is
mostly equivalent to .+\d (“match at least
one character which is not a number, followed by a single number”).
Generally speaking, it runs faster, so we suggest that you try to use
a negated character group instead of a period whenever possible.
Anchoring a match
The ^ and
$
characters are anchors which allow you to anchor your
regular expression to the beginning of the text string or to the end
of it. REGEXMATCH("test0test",
"\d") actually returns TRUE, because there is a single number
in the text string (“test” is ignored). REGEXMATCH("test0test",
"^\d$"), on the other hand, returns FALSE, as the number in
the regular expression is anchored both to the beginning of the text
string and to the end of it, meaning that the “test” parts make the
test fail.
The \b
special character is also an anchor and matches between words. Use it
to separate whole words from one another. REGEXMATCH("testing",
"\btest\b") returns FALSE, because “test” needs to appear on
its own, but REGEXMATCH("this is a test",
"\btest\b") returns TRUE.
Escaping special characters
Finally, if you need to match literal text that is in conflict with
the special characters supported by regular expressions, you need to
escape that text by placing backslashes before the
problematic characters. REGEXMATCH("\d", "\d")
returns FALSE, as “\d” isn’t a number, but REGEXMATCH("\d", "\\d")
returns TRUE, because the extra backslash tells Calcapp that you want
to match a literal backslash followed by “d”.
There are many features supported by regular expressions which we haven’t covered here. If you’re consulting other sources on regular expressions, remember that the flavor Calcapp supports is the JavaScript dialect.
Additional REGEXMATCH features
Google Sheet’s version of REGEXMATCH also accepts two parameters and, with few exceptions, work exactly like Calcapp’s version. Calcapp accepts an additional two parameters, both of which are optional. If you care about bringing Calcapp formulas over to Google Sheets, you may want to ignore the extra parameters.
Set the third parameter to TRUE to make the match case-insensitive.
REGEXMATCH("ABC",
"bc") returns FALSE because of the differences in case, but
REGEXMATCH("ABC",
"bc", TRUE) returns TRUE.
The fourth parameter determines how the ^ and $ characters are
interpreted. By default, ^ anchors the match to
the beginning of the text string and $ to the end of it. By
setting the fourth parameter to TRUE, you can make these anchors
relative to a line instead of the whole text string, if the
text string consists of multiple lines. This is especially useful
with text fields with
multiple lines.
Before demonstrating this fourth parameter, let’s briefly discuss
what a line in a text string really is. When you press
Enter on your keyboard to get a new line, what you’re
doing is that you’re entering a special character, a line break
character. When your computer sees the line break character, it
knows that the text that follows should be presented on a new line.
In Calcapp, you can produce a newline character using the CHAR
formula function with the parameter 10, meaning that the formula
"Line 1" &
CHAR(10) & "Line 2" produces this text string:
Line 1
Line 2
REGEXMATCH("\.$",
"Test string.") returns TRUE, because “Test string.” ends with
a period. (Remember that the period is a special character and must
be escaped with a leading backslash in order to be interpreted
literally.) REGEXMATCH("\.$", "Line 1." &
CHAR(10) & "Line 2") returns FALSE, though, because “Line 2”
doesn’t end with a period and that’s the end of the text string. To
get REGEXMATCH to consider “Line 1.” too and return TRUE, just set
the fourth parameter to TRUE: REGEXMATCH("\.$", "Line 1." &
CHAR(10) & "Line 2"), BLANK(), TRUE.
(Bonus Calcapp fact: Let’s say a formula function accepts four
parameters, where the first two are required and the last two are
optional. If you only provide the first two, the remaining two are
set to their default values. What if you want to provide the fourth
parameter but you’re fine with the default value of the third
parameter? You can’t leave it out, but you can set it to a blank
value. In other words, write BLANK() in place of
that third parameter and its default value is used.)
Finding errors in regular expressions
It’s easy to make errors when writing regular expressions, especially when you’re starting out. Unfortunately, Calcapp Creator won’t complain if you write invalid regular expressions (they’re just text to Calcapp Creator).
Calcapp discovers errors in regular expressions only when you run your app. When it encounters an invalid regular expression, it returns an error value which displays as #VALUE!. If you hover your mouse cursor over #VALUE!, the message Invalid value error in the function “REGEXMATCH” appears, followed by a helpful error message.
Here’s a test app we wrote to ensure that all the formulas above are
correct. We deliberately made a mistake and wrote REGEXMATCH("test0test",
"(^\d$") (with an unclosed parenthesis). As you can see, the
error message “unterminated group” is displayed when you hover your
mouse cursor over the #VALUE! error:
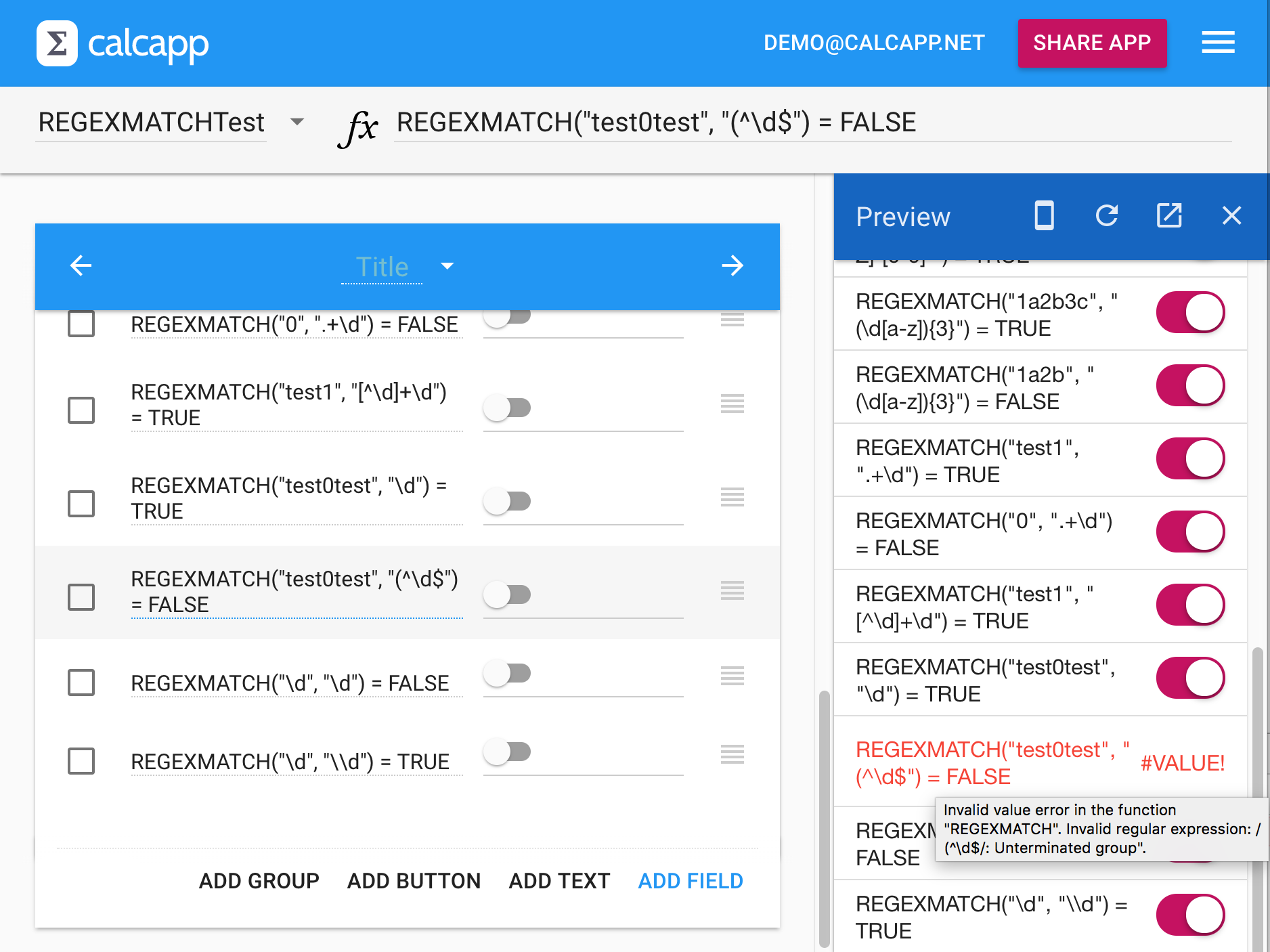
Enclosing part of a regular expression in parentheses makes that part a capturing group (which enables you to extract the characters that are part of the group, as discussed below). If a group is “unterminated,” it means that it’s missing its closing parenthesis.
Important: Errors, such as #VALUE! are only shown when your app is run in the preview sidebar or through connect.calcapp.net. Shared apps never display errors.
Extracting text using REGEXEXTRACT
Use the REGEXEXTRACT function to extract text using regular
expressions. REGEXEXTRACT("This is a test",
"\b\w{2}\b") returns “is”, because that is the only whole word
with exactly two characters.
REGEXEXTRACT("The
combination is 204228", "\d+") returns “204228”, but
REGEXEXTRACT("The
99th combination is 204228", "\d+") returns “99”, because “99”
appears first.
Aside from the two required parameters, which are also supported by
Google Sheets, Calcapp also supports three additional,
Calcapp-specific parameters. We’ll return to the third parameter, but
the fourth parameter makes matching case-insensitive when set to TRUE
(see above) and the fifth parameter, when set to TRUE, makes the
^ and
$ anchors
line-relative as opposed to relative to the entire text string
(again, see above).
The third parameter should be set to a number, which specifies what
capturing group should be returned. A capturing group enables you to
extract very specific parts of a text string and is added to your
regular expressions by enclosing these parts in parentheses. If the
third parameter is not specified (or is set to BLANK()), the entire
text string that matched is returned.
Consider REGEXEXTRACT("The 99th
combination is 204228", "(\d+)[^\d]*(\d+)"). Here’s what the
regular expression means: “Match one or several numbers and capture
them, then match any number of characters which are not numbers and
finally, match and capture one or several numbers.” As it is invoked
without the third parameter, this function returns the entire text
string that matches, that is, “99th combination is 204228.”
If the third parameter is set, though, only a specific group is
returned. REGEXEXTRACT("The 99th
combination is 204228", "(\d+)[^\d]*(\d+)", 1) (the only
difference is that the third parameter is set to 1) returns “99”.
With the third parameter set to 2, “204228” is returned.
Enclosing text in parentheses in a regular expression is useful not
just when you need to extract certain information. As we saw earlier,
(\d[a-z]){3} uses
parentheses to match a number followed by a letter, but only if that
combination is repeated three times. If you need to use parentheses
with REGEXEXTRACT for that purpose and not as a means of extracting
certain information, you can write (?: instead of
( to ensure
that you’re not starting a capturing group.
Replacing text using REGEXREPLACE
The third and final new text-processing function is REGEXREPLACE,
which replaces text using regular expressions: REGEXREPLACE("Abc", "Ab",
"De") returns “Dec”, just like the SUBSTITUTE example used at
the beginning of this post.
REGEXREPLACE is significantly more powerful than SUBSTITUTE, though,
as it uses a regular expression to find the text string to replace.
REGEXREPLACE("The
24th of May, 2019", "\d+", "") removes the first occurrence of
a number in the text string and returns “The th of May, 2019”. It
does this by replacing the first number with the empty text string,
effectively removing it.
REGEXREPLACE requires three parameters, just like its Google Sheets
counterpart. An additional three parameters are optional and specific
to Calcapp. We’ll return to the fourth parameter, but the fifth
parameter makes matching case-insensitive when set to TRUE (see
above) and the sixth parameter, when set to TRUE, makes the
^ and
$ anchors
line-relative as opposed to relative to the entire text string
(again, see above).
The fourth parameter may be set to TRUE if all matches and not just
the first one should be replaced. As such, REGEXREPLACE("The 24th of May,
2019", "\d+", "", TRUE) returns “The th of May, “, effectively
removing both numbers.
You can use capturing groups with REGEXREPLACE, just like with
REGEXEXTRACT. The replacement text, given as the third parameter, can
refer back to these capturing groups by writing a dollar sign
($)
followed by the number of the capturing group. REGEXREPLACE("This is a
sentence", "(\w+)\s+(\w+)\s+(\w+)\s+(\w+)", "$4 $3 $2 $1")
returns “sentence a is This”, reversing the order of the words. The
regular expression captures four words (the special character
\w, which
repeats one or many times), surrounded by spaces (the special
character \s, which repeats one
or many times).
Here’s a less contrived example: REGEXREPLACE("You owe me 42
dollars", "You owe me (-?\d+(?:\.\d+)?) dollars", "The amount you
have to pay is $$$1."), which turns the sentence “You owe me
42 dollars” into “The amount you have to pay is $42.”, correctly
capturing the given number.
There are a few things related to the regular expression that are
worth discussing. First, (-?\d+(?:\.\d+)?) is
used to match and capture a number. The presence of -? enables the number
to be negative, with an optional minus symbol appearing before the
rest of the number. \d+ requires the number
to have at least one integer digit. (?:\.\d+)? captures the
fractional part of the number (the “.19” in “-3.19”) and uses a
non-capturing group starting with (?: as described above.
In order to match a literal period, it has to be escaped, meaning
that it is written \., otherwise the
period would match any character. \d+ matches the actual
fractional numbers. Finally, the group ends with ?, meaning that numbers
don’t have to have fractional parts in order to match.
The replacement text string, “The amount you have to pay is $$$1.”, includes three dollar signs in a row. The first two dollar signs signify that a single literal dollar sign should be included – in replacement text strings, that’s how literal dollar signs must be written. The third dollar sign, followed by “1”, references the first capturing group and inserts the text string it captured.
Matching letters not in English
As we have seen, [a-zA-Z] can be used to
match letters in English. Unfortunately, this only works for the 26
letters of the English alphabet. \w won’t work either,
as it’s simply a concise way of writing [a-zA-Z0-9_].
To match a letter in any language, write p{L} instead. To match
any character which is not a letter, write \p{^L}. REGEXMATCH("日本語",
"\w+") returns FALSE, but REGEXMATCH("日本語",
"\p{L}+") returns TRUE.
\p enables
characters to be chosen from various categories, where letters are
just one category of many. Another useful category is made up of
currency symbols like “$”, “€” and “¥”. Match currency symbols using
the “Sc” category, meaning that REGEXEXTRACT("$42",
"\p{Sc}+") returns “$”.
For a more on regular expressions, read about our latest sample app, which uses regular expressions extensively.